
white cloud in vault type room representing cloud computing
This blog post was authored by Sarah Lemaire.
On Tuesday, August 22, The Boston Vertica User Group hosted a late-summer Meetup to talk to attendees about compute engines and data mart applications, and the advantages and disadvantages of both solutions. In the cozy rustic-industrial atmosphere of
Commonwealth Market and Restaurant, decorated with recycled wood pallets, the group of Vertica customers, prospective customers, employees, and just folks interested in data analytics sampled the quirky beer offerings (check out the Lemongrass Saison on draft, brewed by the Maui Brewing Co. in Kihei, HI) before talking about distributed machine learning for big data.
Waqas Dhillon of Vertica with Bryan Whitmore gave a short presentation focused on organizations getting insights from their data in real time, and which solution can make that happen quickly and accurately. Specifically, Waqas talked about compute engines, using Spark as an example, and data marts, using Vertica as the example. The biggest advantages that data marts have, he explained, are built-in data storage for handling large amounts of data while performing analytics in place and high concurrency in order to process the data quickly, supporting multiple users.
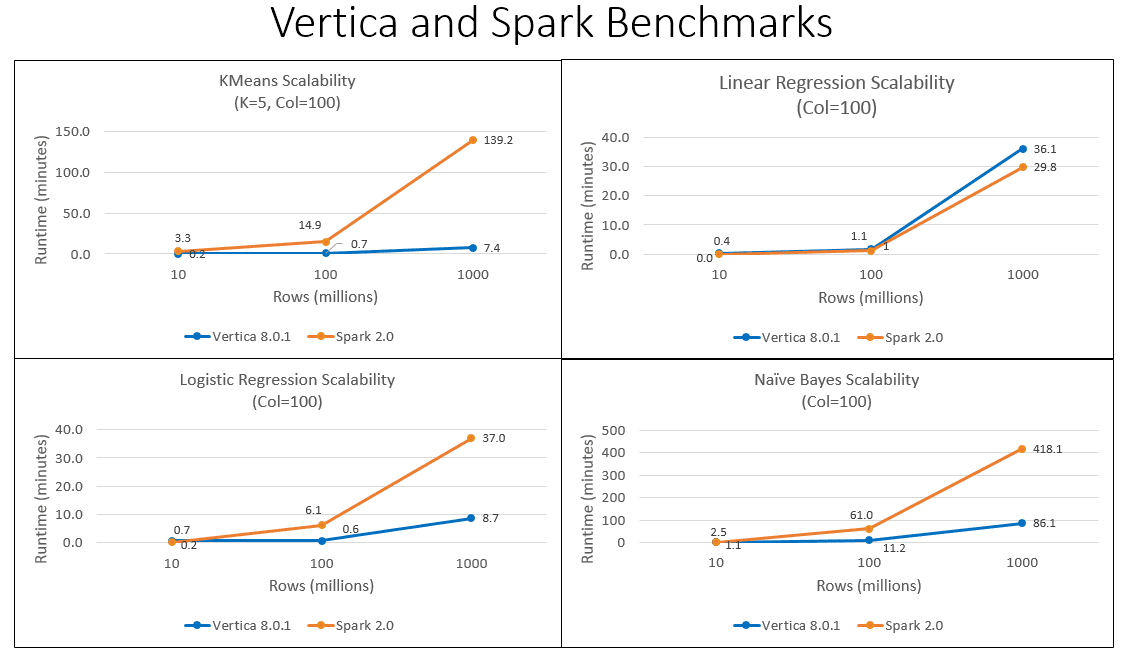
To illustrate his point, Waqas used machine learning analytics. His benchmarks show that when running KMeans, Linear Regression, Logistic Regression, or Naïve Bayes algorithms, Vertica has minor performance advantages over Spark with relatively small amounts of data. But as the amount of data increases, Vertica provides, in most cases, orders of magnitude better performance than the same machine-learning algorithms running in Spark using the exact same architecture. While Vertica numbers include the time it takes to load data from disk to memory, the data loading times for Spark are not included in the performance comparison graphs to give Spark an unfair advantage.
Then Waqas compared the steps needed to train and test a Random Forests model in both Spark and Vertica. The example he used was classifying bank loans as low, medium, or high risk. Because Spark has to import the random forest libraries, and load and convert the data before running the model, performing the calculations is more complicated: 28 lines of code in Scala is required compared to just 7 lines of SQL in Vertica to run a Random Forest model.
Waqas finished his presentation by evaluating the needs of organizations that focus on four types of architecture considerations: data demand, organizational structure, accuracy requirements, and deployment configurations. For each area, Waqas drilled down into specific considerations and identified whether a compute engine (CE) or data mart (DM) would be the right solution. The following images capture his recommendations.




After the presentation, attendees asked Waqas and Bryan questions about storage, pricing, and competing products that were not mentioned in the presentation. People lingered for a while, asking more questions and swapping stories.
We forgot to try the chocolate bourbon ice cream before we left, but we enjoyed meeting our customers and others. See you at the next Boston Meetup!





