

The Vertica Connector for Apache Spark is a fast parallel connector that allows you to use Apache Spark for pre-processing data. Apache Spark is an open-source, general purpose, cluster-computing framework. The Spark framework is based on Resilient Distributed Datasets (RDDs), which are logical collections of data partitioned across machines. For more information, see the Apache Spark website.
Prerequisites
Before you use the Vertica Connector for Apache Spark, you must:
• Install and configure Vertica according to the Administrator’s Guide
• Install your Apache Spark clusters
• Have an HDFS cluster to use as an intermediate staging location
How Vertica and Spark Work Together
Using the Vertica Connector for Apache Spark you can save data from a Spark DataFrame to Vertica tables using the DataSource API.
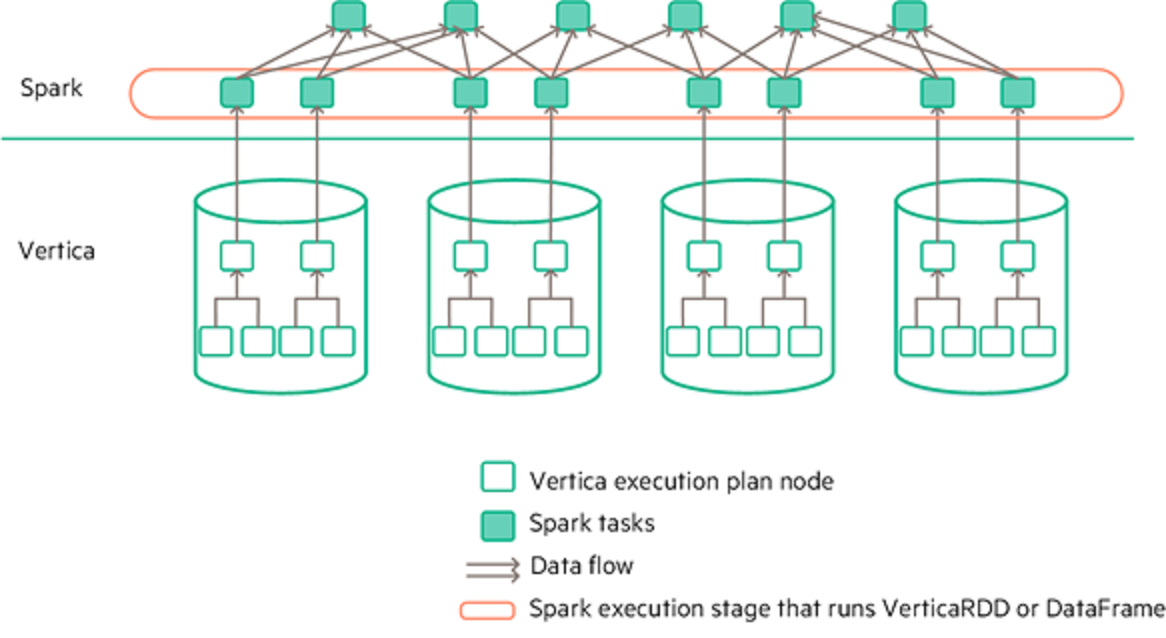
The following graphic shows the runtime behavior of the connector when moving data from Vertica to Spark:
Set Up
To set up the connection from Vertica to Apache Spark, you need the following two JAR files:
• Vertica Apache Spark connector JAR file
• Vertica JDBC driver JAR file
You can use the connector by including the two JAR files in the –jars option when invoking spark-submit or spark-shell. To do so, complete the following:
1. Log on as the Spark user on any Spark machine.
2. Copy both the Vertica Spark Connector and Vertica JDBC JAR files from the package to your local Spark directory.
3. Run the connector using either spark-submit or the spark-shell:
a. Using spark-submit:
./bin/spark-submit –-jars hpe-spark-connector-8.0.0-0.jar,vertica-jdbc-8.0.0-0.jar \ myapp.jar
b. Using spark-shell:
./bin/spark-shell –-jars hpe-spark-connector-8.0.0-0.jar,vertica-jdbc-8.0.0-0.jar \
You can also use the connector by deploying it to a Spark cluster so that all Spark applications have access across all nodes. To do so, complete the following:
1. Copy the files to a common path on all Spark machines.
2. Add the path for the connector and JDBC driver to your conf/spark-defaults.conf and restart the Spark Master. For example, modify the spark.jars line by adding the connector and JDBC JARS as follows (replace paths and version numbers with your values):
spark.jars /common/path/hpe-spark-connector-8.0.0-0.jar,/common/path/vertica-jdbc-8.0.0-0.jar
DefaultSource API
The Vertica Connector for Apache Spark implements the DefaultSource API to move data from Spark to Vertica, as well as loading Vertica data into a Spark DataFrame. The API provides generic key-value options for configuring the database connection and tuning parameters and other options.
Write data from a Spark DataFrame to a Vertica table using the Spark df.writ.format () method.
Read a Vertica table into Spark by invoking the SQLContext.read.format() method.
From Spark to Vertica
Using parallel read and write from HDFS, the connector can load large volumes of data from partitions distributed across multiple Spark worker-nodes into Vertica. To simplify writing data from a Spark DataFrame to a Vertica table, use the com.vertica.spark.datasource.DefaultSource API with the Spark df.write.format () method, as shown here:
df.write.format("com.vertica.spark.datasource.DefaultSource").options(options).mode(save mode).save()
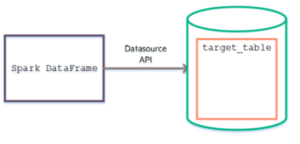
To save your Spark DataFrame to Vertica, you must specify the following required parameters as options:
| Parameter | Description |
|---|---|
| table | Target Vertica table to save your Spark DataFrame. |
| db | Vertica database |
| user | Vertica user. (Must have CREATE and INSERT privileges in the Vertica schema) |
| password | Password for the Vertica user. |
| host | Hostname of a Vertica node. This value is used to make the initial connection to Vertica and look up all the other Vertica node IP addresses. You can provide a specific IP address or a resolvable name such as myhostname.com. |
| hdfs_url | Fully-qualified path to a directory in HDFS that will be used as a data staging area. For example: hdfs://myhost:8020/data/test
You must first configure all nodes to use HDFS. See Configuring hdfs:/// Access. |
In addition to the required parameters, you can specify additional options. Read about optional parameters in the Vertica documentation.
You’ll also specify the DataFrame SaveMode, which specifies the expected behavior of saving a DataFrame to Vertica.
Here are your different SaveMode options:
• SaveMode.Overwrite: overwrites or creates a new table.
• SaveMode.Append: appends data to an existing table.
• SaveMode.ErrorIfExists: creates a new table if the table does not exist, otherwise it errors out.
• SaveMode.Ignore: creates a new table if the table does not exist, otherwise it does not save the data and does not error out.
The save( ) operation never results in a partial or duplicate save. The connector either saves the DataFrame in its entirety to the target table successfully or it aborts the save. In case of failures, to avoid leaving the target table in an inconsistent state, the connector:
1. Saves the data to HDFS as an intermediate staging location
2. Safely copies it into the actual target table in Vertica
You can monitor the save process by consulting the S2V_JOB_STATUS_USER_$USERNAME$ table.
From Vertica to Spark: Loading into a Spark DataFrame
To load Vertica table data into a Spark DataFrame, use the DefaultSource API with the Spark sqlContext.read.format() method:
sqlContext.read.format("com.vertica.spark.datasource.DefaultSource").options(...)
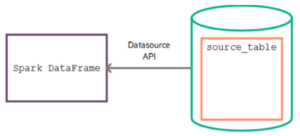
To connect, you must specify the following required parameters as options:
| Parameter | Description |
|---|---|
| table | Target Vertica table or view to save your Spark DataFrame. The Vertica table must be segmented by hash or by an expression that returns non-negative integer values. Also, if the Vertica table is an external table, the underlying file(s) on which the external table is based must be accessible on all Vertica nodes. |
| db | Vertica database. |
| user | Vertica user. (Must have CREATE and INSERT privileges in the Vertica schema) |
| password | Password for the Vertica user. |
| host | Hostname of a Vertica node. This value is used to make the initial connection to Vertica and look up all the other Vertica node IPs. You can provide a specific IP address or resolvable name such as myhostname.com. |
| numPartitions | (Optional) Number of Spark partitions for the load from the Vertica job, each partition creates a JDBC connection. Default value is16. |
| dbschema | (Optional) Schema space for the Vertica table. Default value ispublic. |
| port | (Optional) Vertica Port. Default value is 5433. |
From Vertica to Spark: Loading into a Spark RDD
The Vertica Connector for Apache Spark includes a Vertica RDD API, which simplifies creating an RDD object based on a Vertica table or view.
You can create a VerticaRDD object either by initiating it or by calling one of the following three RDD.create methods:
• create(sc, connect, table, columns, numPartitions, mapRow)
• create(sc, connect, table, columns, numPartition, ipMap, mapRow)
• create(sc, host, port: Int = 5433, db, properties, table, columns, numPartitions, mapRow)
The parameters for the Create methods are:
| Parameters | Description |
|---|---|
| sc | Spark Context object. |
| connect | Connection object that contains a function that returns an open JDBC Connection. |
| table | String value for the database table name |
| columns | Array[String] that contains the columns of the database table that will be loaded. If an empty array, this RDD loads all columns. |
| numPartitions | Integer value specifying the number of partitions for the VerticaRDD. |
| ipMap | Map [String, String] containing the optional map from private IP addresses to public IP addresses for all Vertica nodes. This map is used only when Vertica is installed on private IP addresses but is listening on both private and public IP addresses. |
| mapRow | Function from a ResultSet to a single row of the upi result types you want. This function should call only getInt, getString, etc; the RDD takes care of calling next. The default maps a ResultSet to an array of Object. |
| host | String containing the host name (or IP address) of a Vertica node, that can be used to connect to Vertica. |
| port | Integer value specifying the number for Vertica connection. Default value is 5433. |
| properties | Properties object for JDBC connection properties, such as user, password. |
For more information about integrating with Apache Spark, see the Vertica documentation.
About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!


