


Business Team Meeting Discussion Working Concept
This blog was updated in July 2018.
Overview
As of Vertica 9.1.x, you can operate your database in Eon Mode. Eon Mode separates the computational processes from the storage layer of your database. Deployment of Eon Mode is limited to Amazon Web Services. In some ways, Eon Mode is different than the traditional Vertica Enterprise mode. Loading your data effectively can make a big difference in how you take advantage of accommodating variable-demand workloads. To better understand loading in Eon Mode, let’s take a look at a use case.Loading from S3
This post assumes that the source data is on S3. This post is intended for customers loading from S3 and not from the local disk(s).While loading your input data is the same in Eon Mode as it is in Enterprise mode, there are some considerations to keep in mind. This example walks through those. Suppose you want to load one big file located in the default US East Amazon region. There are two ways you can do this:
1. Download the file and then load it using COPY FROM STDIN/ COPY FROM LOCAL’
a. This option will work, but it can be slow and is not recommended. When you use this option, you pay the cost of data transfer twice: once from S3 to the local disk and another time from disk to Vertica.
2. Use the UDFS to copy from S3 COPY t FROM ‘s3://bucket/file…’
a. This is the best option because it supports apportioned load of the file from different nodes.
While any of these ways will work, you may want to choose a specific way if you encounter a few different scenarios.
Scenario 1: What if you want to load a file in a different region, such as US West?
If your file is in a different region, you can use either option, but you should not use option 1 for the reasons discussed previously. To use it in option 2, you need set AWSRegion configuration parameter at session level: alter session set AWSRegion=’us-west-1’.
Scenario 2: What if the AWS endpoint is different?
If you encounter different AWS endpoints, you must do some tweaking. You may need to set the AWSEndpoint configuration parameter. This is also a global parameter. For more information, see AWS Parameters in the Vertica documentation.
Scenario 3: What if my file is compressed?
If your file is compressed, you need to specify input-format as GZIP in the UDFS copy command. However, this disables the UDFS’s ability to load different portions of the file from different nodes. See COPY examples for more information.
Loading from Management Console
You can also use Management Console (MC) to load data from S3 into Vertica Tables and view the results of data loading.You can access the “Load” page from the “Load” tab on the bottom of the Overview page. From the “Load” page, you can view two types of data in the table. For S3 data, you should use the “Instance” tab, which allows a single load process of data.
From the “Instance” tab, select the New S3 Data Load button and fill out the form. You can choose to use IAM Role Authentication (For S3 buckets created or owned in the same account or corporate account), or enter an AWS key credential (for accessing another user’s bucket via authentication).
Depending on the type of data, you can add additional parameters for the COPY statement that will be generated. Behind the scenes, MC uses UDFS to copy from S3 S3 COPY t FROM ‘s3://bucket/file…’

Results of the load process will be displayed in the load history table. You can see the results of all load processes including any command line or batch scripting. Note that data loads initiated from MC have the stream name ‘MC_S3_Load’. For more information, see Loading Data Using MC.
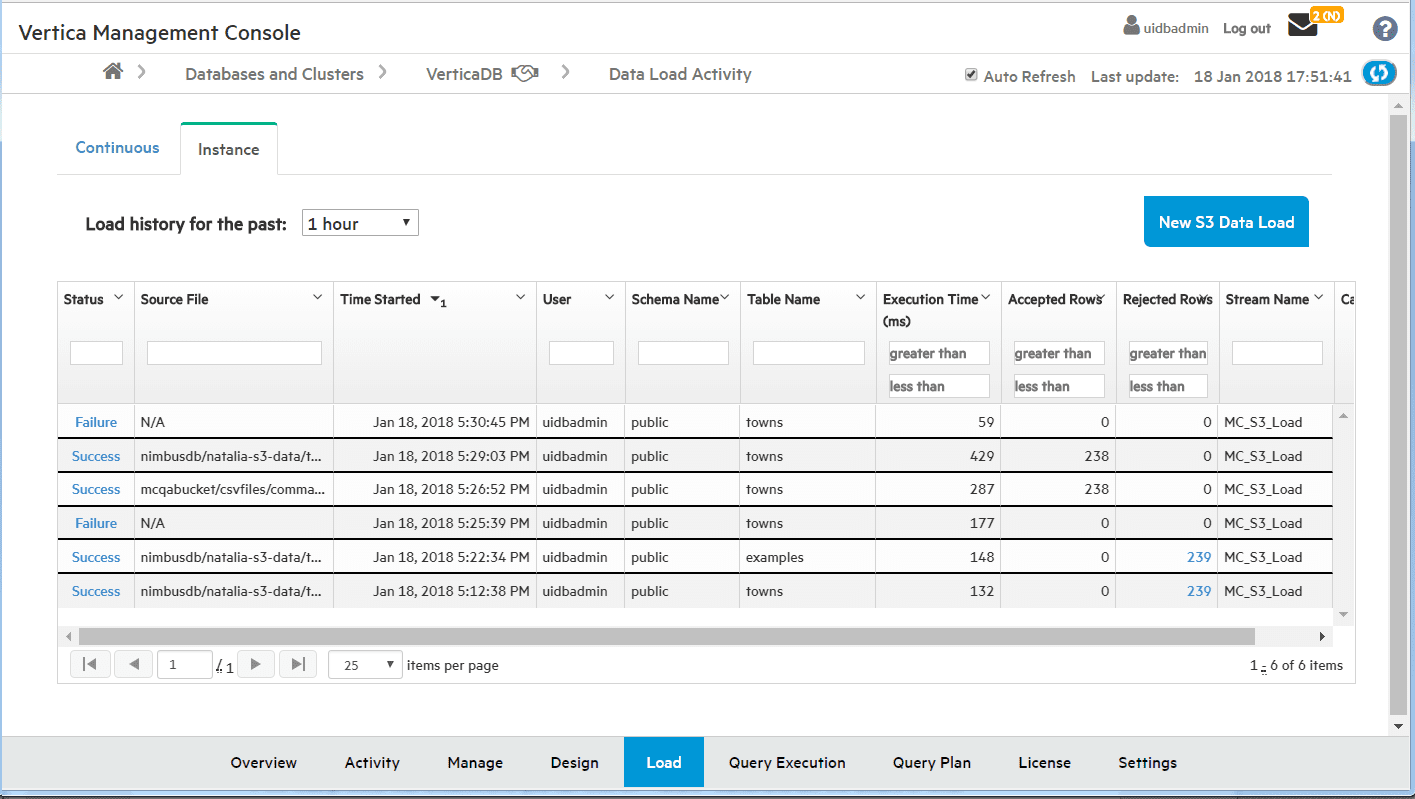
If the load process was unsuccessful, you can click on the “Failure” status and see the details of what went wrong. In the example below, the name of the file in the bucket was incorrect.

To complete the circle, you can use MC to start querying your data right after loading. Select the “Query Execution” tab and enter your queries:

For more information, see Loading From an S3 Bucket in the Vertica documentation.
About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!


