


If you experience performance issues, your best first step is to run Database Designer with sample queries and sample data. Database Designer creates projections that are optimized for those queries and data.
It’s a good idea to run Database Designer in a test environment first so you can review its projection recommendations before deploying the database design. You can also manually create projections based on the recommendations from Database Designer. However, Database Designer does an excellent job of designing projections for your specific workload automatically.
Let’s look at a simple example table that contains information about retail transactions.
=> CREATE TABLE transactions (tr_date DATE, amount FLOAT, dept VARCHAR);
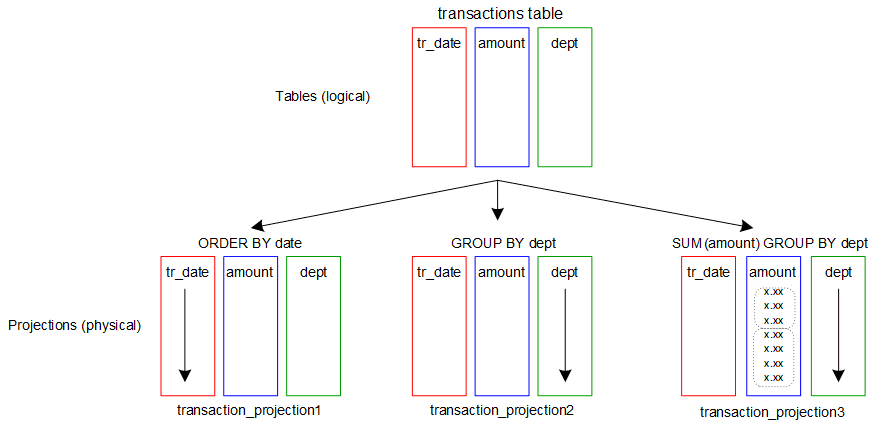
Suppose you frequently run a query that returns all transactions since a specific date:
=> SELECT * FROM transactions ORDER BY tr_date WHERE tr_date > '2015-05-09';
Because projection transaction_projection1 is already sorted by the date column, the Optimizer might choose it to execute this query. When that happens, to return the correct results, Vertica has to read only those rows from the database.Or, suppose you want data about each transaction by department, because you want to compare the sales among departments. Given the following query:
=> SELECT * FROM transactions ORDER BY dept;
The Optimizer might choose transaction_projection2. This projection already orders the transaction table data by dept, so Vertica does not have to re-sort it to return the query results. Now suppose you want to see the sum of all transactions for each department.
=> SELECT SUM(amount) FROM TRANSACTIONS GROUP BY PIPELINED dept;
In this situation, the Optimizer might use transaction_projection3, which pre-aggregates the transaction amounts and sorts them by dept. You can specify that Vertica use the GROUP BY PIPELINED algorithm, which is much faster than the GROUP BY HASH algorithm. For more detailed information, see our Knowledge Base article about Redesigning Projections for Query Optimizations.
For More Information
See the following sections of the Vertica documentation:• Query Optimization
• Data Storage and Projections
• Creating a Database Design
About the Author
Sarah Lemaire
Manager, Vertica Documentation



